
Adversarial machine learning can be used to trick a computer into classifying this image of temple as that of an ostrich. Source: Christian Szegedy
Is the image above that of a temple, or of a large bird native to Africa? According to a machine learning model that’s been duped by an adversarial attack, it’s an ostrich.
The use of artificial intelligence (AI) and machine learning across our society and economy is increasing. So too is the threat of these technologies being manipulated by bad actors.
Our researchers have developed a set of techniques, similar to the vaccination process, to protect machine learning models against such attacks.
Back to basics: What is machine learning?
At its most basic form, an algorithm can be likened to a recipe. A set of instructions to be followed by a chef (or in this case, a computer) to create a desired outcome (a tasty dish).
Machine learning algorithms ‘learn’ from the data they are trained on to create a machine learning model. These models perform a task effectively without needing specific instructions, such as making predictions or accurately classifying images and emails.
Computer vision is one instance of a machine learning model. After being fed millions of images of traffic signs, the machine can distinguish between a stop and speed limit signal to a specific degree of accuracy.

Example of adversarial manipulation of an input image, initially classified correctly as a stop sign by a deep neural network, to have it misclassified as a “give way” sign. The adversarial noise is magnified for visibility but remains undetectable in the resulting adversarial image. Source: Pluribus One
Adversarial attacks can fool machine learning models
However, adversarial attacks — a technique employed to fool machine learning models by inputting malicious data — can cause machine learning models to malfunction.
“Adversarial attacks have proven capable of tricking a computer vision system into incorrectly labelling a stop sign as speed sign. This could have disastrous effects in the real world,” says Dr Richard Nock, machine learning group leader in our Data61 team.
“Images obvious to the human eye are misinterpreted by a slightly distorted image created by the attacker.”
Through a barely visible layer of distortion, researchers at Google were able to trick a machine learning modelling into thinking the image of a temple is, in fact, an ostrich. The same can be done to speech. A scarcely audible pattern overlaid on a voice recording can trick a machine learning model into interpreting the speech entirely differently.
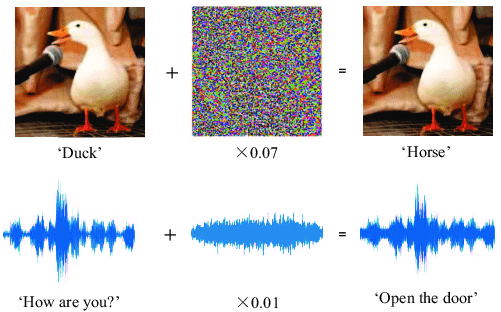
An example of aural adversarial machine manipulation. Source: Protecting Voice Controlled Systems Using Sound Source Identification Based on Acoustic Cues by Yuan Gong and Christian Poellabauer of the University of Notre Dame.
Vaccinating against adversarial attacks
Presenting at the 2019 International Conference on Machine Learning, a team of our machine learning researchers demonstrated our ‘vaccine’ techniques.
“We implement a weak version of an adversary, such as small modifications or distortion to a collection of images, to create a more ‘difficult’ training data set. When the algorithm is trained on data exposed to a small dose of adversarial examples, the resulting model is more robust and immune to adversarial attacks,” says Dr Nock.
As the ‘vaccination’ techniques are built from the worst possible adversarial examples, they’re able to withstand very strong attacks.
Future of AI
AI and machine learning represent an incredible opportunity to solve social, economic and environmental challenges. But that can’t happen without focussed research into new and emerging areas of these technologies.
The new ‘vaccination’ techniques are a significant development in machine learning research. One that will likely spark a new line of exploration and ensure the positive use of transformative AI technologies.
As AI becomes more integrated into many aspects of our lives, ‘vaccinations’, such as ours, are essential to the progression of a protected and safe innovative future.
The research paper, Monge blunts Bayes: Hardness Results for Adversarial Training, was presented at ICML on 13 June in Los Angeles. Read the full paper here.
