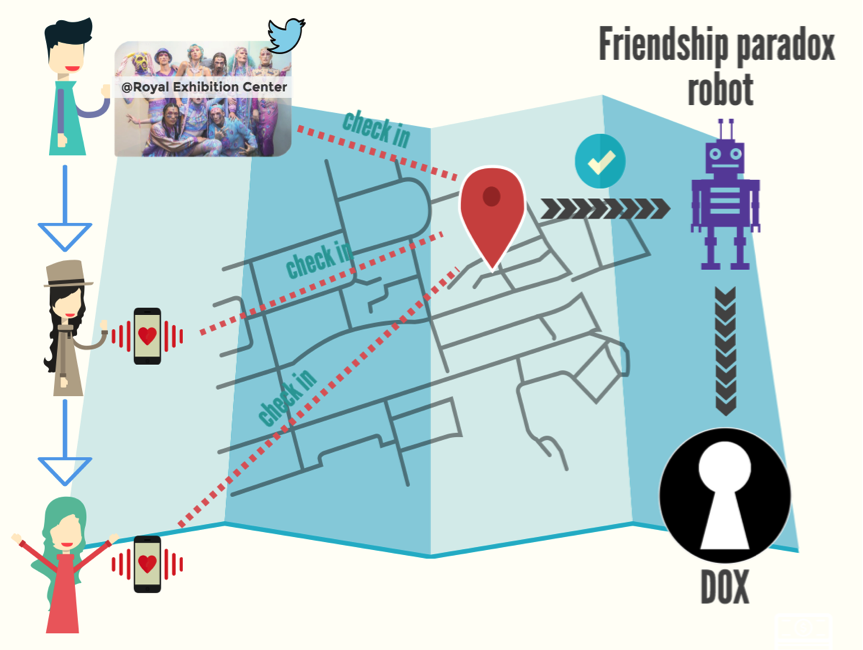
We took advantage of the friendship paradox and big data from social media to create 'Dox', an app that helps you find out 'the happs'.
Share this
Do you ever feel that most of your friends are more socially connected than you? Do they seem to learn about all the cool new hangouts — bars, cafes, pop-up shops, etc — before you do?
If it’s any consolation, they do, and it’s not your fault. It’s a manifestation of the ‘Friendship Paradox’, a phenomenon first observed by the sociologist Scott L Feld in 1991. Simply put it says: “your friends have, statistically speaking, more friends than you do.” It’s a consequence of the mathematical properties of the social networks in which we live.
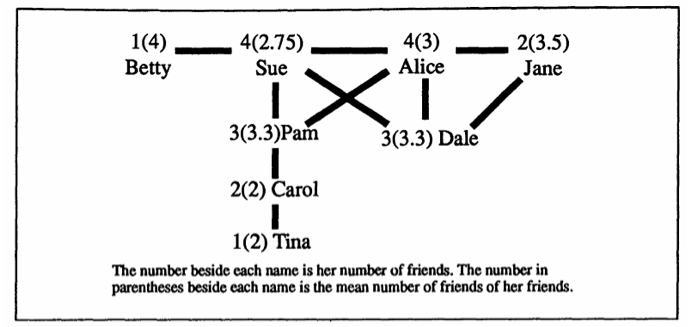
The figure below (adapted from Feld’s paper) shows an example of a small friendship network from a high school. The number beside each name is her number of friends, and the number in parentheses beside each name is the mean number of friends of her friends. This network shows that only the highly connected students like Sue and Alice have more friends than their friends do —the overwhelming majority of the rest of us do not, and that’s why the experience the Friendship Paradox firsthand. Interestingly, this social phenomenon has surprising, wide-ranging uses.
Until recently the Friendship Paradox was considered a theoretical finding, a curiosity if you may. But today is different from the 90s: there are millions of people publicly tweeting many times every day: about what they are doing; about where they are doing it; about hot topics of the moment such as the latest celebrity antics, or the threat of bad weather.
So back in 2010 we decided to download and analyse all these data and see if the Friendship Paradox would hold in the social media hyper-connected world. We found not only that the paradox was even stronger in the social media world, but that it could be applied in quite a few unexpected scenarios.
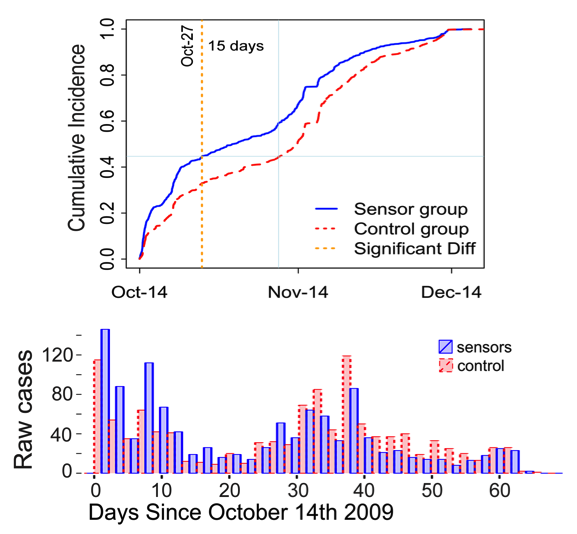
For example, we used it to combat the spread of contagious diseases. When they are sick, people tweet about their illness and people like Sue and Alice who have high connectivity within their network are more vulnerable to viral infections. By analysing the tweets of the most connected people we observed symptoms propagating through the social network. The diagram below shows how analysis of Twitter messaging about a viral infection can distinguish between the better socially connected people ‘sensor group’ and the general population who following them ‘control group’ and how the better connectedness of the sensors results in them contracting infections earlier than the controls. By monitoring the difference in infection time between those two groups, it is possible to make early detection of an outbreak — a direct application of the Friendship Paradox.
This diagram shows how analysis of Twitter messaging about a viral infection can distinguish between the better socially connected people ‘sensor group’ and the general population ‘control group’ and how the better connectedness of the sensors results in them contracting infections earlier than the controls.
It’s also possible to use the Friendship Paradox to improve the distribution of warnings of major natural events such as hurricanes, and, in our most recent work, to help people find the latest ‘in’ venues in major cities.
These are all aspects of computational social science being studied by Data61, the Data Science branch of CSIRO. Computational social science is the use of computers to model, simulate and analyse social phenomena. It’s a new field of scientific endeavour made possible by the availability of unprecedented amounts of data about human interactions in different social spheres and environments. This fascinating field combines computer modelling, statistical analysis, network theory and — most interestingly — the study of human behaviour at large scale through the footprints we leave in the digital world. These data open the possibility to leverage knowledge about social behaviour beyond research based only on small samples of people.
The Human Dynamics team within Data61 epitomises the fusion of the various fields and skills that form the discipline of computational social science. I oversaw the formation of, and now lead, a team that includes Yury Kryvasheyeu (a physicist), Caron Chen (an expert in geographic information systems) and Marian-Andrei Rizoiu (a computer scientist). I recruited Caron and Yury in 2012, and Marian-Andrei later in 2013.
Yury came to Data61 with a background in classical applied physics and a PhD in computational materials science. He worked initially on flood modelling as part of Data61’s Disaster Management Project. He started looking at the massive Twitter datasets generated by large-scale disasters and soon found himself drawn into the exciting world of big data and social science.
Marian-Andrei’s first experience with Data61 was a one-month research visit in 2013. He was finishing up a PhD in data mining and machine learning in Lyon, France during which he specialised in detecting and analysing temporal patterns.
I met him during that visit and was thinking how similar temporal analysis could be applied to large corpora of data to detect a phenomenon we coined as “privacy deflation” — the erosion of users’ privacy in online environments resulting from the traces they leave behind.
Marian-Andrei is now collaborating with the rest of the team to analyse and develop a theoretical model for popularity in the online world. He and colleagues at the Australian National University have constructed a system for early identification of potentially viral YouTube videos, by capturing and modulating the signal detected in millions of tweets.
In the Human Dynamics team at Data61 we have a particular interest in exploring how social networking makes it easier to find people and solve real-world problems: we specialise in search and discovery for rare information mediated by crowds. In collaboration with researchers at other institutions around the world we’ve applied the Friendship Paradox to analyse Twitter activity before, during and after Hurricane Sandy.
Hurricane Sandy hit the US East Coast on 29 October 2012. It destroyed or damaged 650,000 buildings, left 8.5 million people without power and caused damage estimated to be in excess of $US50 billion.
Not surprisingly we found that the real and perceived threat of Hurricane Sandy — together with the physical disaster effects — were reflected in the intensity and composition of Twitter’s message stream. More importantly we found that per-capita Twitter activity strongly correlated with the per-capita economic damage inflicted by the hurricane.
This suggested to us the possibility that massive online social networks could be used for rapid assessment of damage caused by a large-scale disaster. We applied the principles of the Friendship Paradox to identify members of what we called ‘sensor groups’ — the better-connected people tweeting about Sandy — and compared these to randomly selected control groups. We found that sensor group members enjoyed considerable lead-time in their awareness of the impending disaster.
Hurricanes are highly predictable using standard meteorological techniques, but we believe following the tweets of the better-connected members of society can aid the detection of, and dissemination, of information on both natural and man-made disasters.
However, there is another important aspect of these better-connected members of society that we have been exploring, in collaboration with researchers from Spain, Switzerland, Singapore, and the US.
We found that such individuals could be bellwethers for population-wide phenomena that might be hard to detect because of the sheer volume of data or the difficulty of accessing those data for an entire population.
Our research demonstrated the potential to apply the Friendship Paradox and the new techniques developed by computational social science to derive very real social benefits, but these benefits can only be realised with systems to ingest, process and analyse large volumes of data, along with sophisticated software tools and expertise to extract valuable and actionable information.
Caron has managed to combine the power of cloud computing and smartphones to create an iPhone app, DOX, that can analyse Twitter feeds and exploit the Friendship Paradox to deliver useful information to people who would like to be better connected socially.
PARADOX works for seven cities — Los Angeles, Melbourne, New York, San Francisco, Singapore, Sydney and Tokyo. It analyses the Twitter feed from people located in these cities, along with other social network feeds, and uses these data to locate trending venues and other social developments before they become mainstream.
Caron has spent about six months developing the app and he faced quite a few challenges. Twitter makes available to external parties one percent of all tweets and also the approximately one percent that contain location information — these are tweets where the tweeter has attached geotagging information. All up, he’s getting between two and three million tweets every day from all seven cities. Caron tried to expand the city list, but the computational capacity he had available could not accommodate it, nor did he have access to storage sufficient for the volume of tweets that would have collected. We need to buy more servers!
What Twitter does not provide, and what is essential to the application of the Friendship Paradox, is any information on who follows whom on Twitter. Caron used his own analysis to infer these networks, and now has a database of more than one billion links between Twitter users.
Although the app shows only trending locations in the seven cities, Caron has information on more than 5,000 locations across these cities. A possible enhancement to the app would be to allow users to select which cities they want information on.
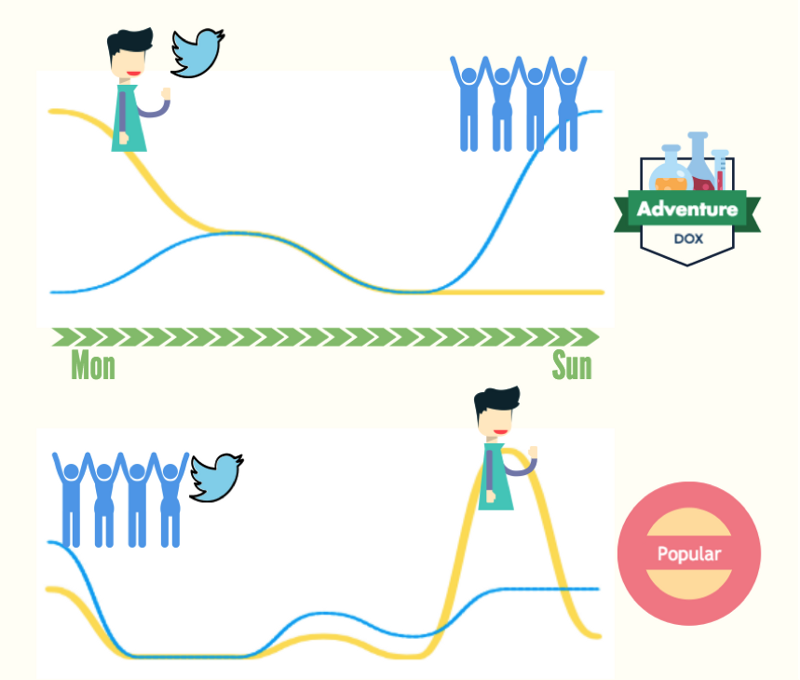
The app revealed the power of the Friendship Paradox. Locations could be easily divided into three categories based on their propagation patterns on Twitter (two distinct patterns are shown in the figure above):
Adventure spots which hip people were always the first to discover, followed by ‘the crowd’;
Popular spots that both hip people and the crowd visited at roughly the same time;
Tourism places that hip people and the crowd visited at roughly the same time, but where the sizes of sensor groups — the better-connected people — and randomly selected control groups were comparably smaller than the total number of visitors. For instance, a tourism place could have 10,000 individual visitors every week, only a very small portion of whom had social links on Twitter, say 1%, i.e., 100 users. Because the target users of PARADOX are ‘hipsters’, those tourism places are not shown.
Caron is no stranger to mobile app development. Before joining Data61’s predecessor, NICTA, in 2012 he was a PhD student at the University of Melbourne. There he and a fellow PhD student launched a startup, Nearbyr, and an app of the same name designed to help restaurants attract customers.
He recalls: “It was the beginning of the era for location-based apps, for example FourSquare, but that was not so popular back in 2012. We figured that we could help businesses attract people by offering free coffee or free meals.”
Nearbyr enjoyed early success: seven restaurant chains in Melbourne signed up, along with individual stores from the Jamaica Blue and Movenpick chains. Jamaica Blue made 10,000 free coffees available to users of the app to promote uptake, but Caron and his partner quickly ran out of funds, and Caron went looking for a job, when his entrepreneurial foray with Nearbyr stood him in good stead.
“I met Manuel in late 2012, and submitted an application to Data61,” he says. “He wanted someone who combined a research background with startup experience. I had a very long interview over four or five hours with six or seven people individually, and I got the job.”
The Human Dynamics team at Data61 is now transitioning into research applying computational models to Urban Science — we are using massive datasets — from a variety of sources — that describe human activity. Our goal is to understand and address real-world challenges in urban planning and development.
Our efforts were boosted significantly recently when we received an excellence prize as one of over 800 teams competing in the Shanghai Commission of Economy and Information Technology’s Shanghai Open Data Apps (SODA) contest. For the contest the Shanghai Government made available over 400 Gigabytes of spatial-temporal data on people’s use of public transport including, taxis, buses the metro.
Armed with these data Caron is researching how people interact as they move about in cities. For a number of cities in Australia and elsewhere he’s looking at how the data can be used to aid transport planning and community development.
We’ve shown how fundamental research in data science can lead to new applications that would be otherwise impossible to create. We are “shooting for the moon” by diving into these new, weird, massive, hard-to-clean datasets, and along the way … perhaps build the next generation of social media.
Understanding the behaviour of populations has long been an obsession for many disciplines: marketeers, sociologists, forecasters, demographers. Sampling by survey has long been a favoured tool, but today the massive volumes of data generated by individuals in our connected society hold the potential to provide much richer and more accurate insights into the movement, interests and activities of entire populations.
The challenge for computational social science is to develop tools and techniques to make the analysis of data and the extraction of useful insights affordable and easy to use, like PARADOX.
For example, PARADOX could be developed into a commercial product for advertising agencies to help them identify the cool places where the hipsters hang out for some super targeted advertising campaigns. Such a project could even be the beginnings of another startup for Caron and Data61.
One last thing …
Caron wanted to see how good PARADOX’s recommendation can be. So together with his wife and their son, they visited a new restaurant in Melbourne recommended by PARADOX during the weekend — and it turned out that PARADOX worked so well that … they had to spend two hours in waiting in line to get a table!


23rd May 2016 at 11:48 am
Do you know what “doxxing” is? I’d suggest a name change for your app might be in order!
17th May 2016 at 5:10 pm
I have much better things to do than stand in line for 2 hours ,,,
17th May 2016 at 2:03 am
This reinforces the view that one need be very careful about those topics discussed over the internet. An ideal way for spreading rumours.