
Over three decades, the internet has grown from a small network of computers used by research scientists to communicate and exchange data to a medium that has penetrated almost every aspect of our day-to-day lives. It’s hard to imagine a life without online access for business, shopping, and socialising.
But the technology that has connected us at a scale never before possible has also amplified some of our worst qualities. Online hate speech spreads across the globe, with short and long term consequences for individuals and societies.
These consequences are often difficult to measure and predict. Online social media websites and mobile apps have inadvertently become the platform for the spread and proliferation of hate speech.
Our Data61 and StellarGraph’s team of graph analytics experts looked at whether they could detect hateful users based on their activities on Twitter.
How graph machine learning is detecting hate speech
We developed and compared two machine learning methods for classifying a small subset of Twitter’s users as hateful, or not hateful. To do this we used a freely-available dataset of Twitter users published in 2018 by researchers from Universidade Federal de Minas Gerais in Brazil.
First, we employed a traditional machine learning method to show the probability of a certain situation, providing clear yes/no-style answers. That was used to train the machine based on a users’ vocabulary and social profiles.
Next, we applied a state-of-the-art graph neural network (GNN) machine learning algorithm called Graph Sample and Aggregate (GraphSAGE) to solve the same problem. But we added in the relationships between users.
Introducing: the dataset
The dataset covers over 100,000 Twitter users. For each user, a number of activity-related features are available. This includes the frequency of tweeting, the number of followers, the number of favourites, and the number of hashtags.
An analysis of each user’s vocabulary derived from their last 200 tweets gave us more information. We used Stanford’s Empath tool to analyse each user’s lexicon in categories such as love, violence, community, warmth, ridicule, independence, envy, and politics. Then we assigned numeric values indicating the user’s alignment with each category.
In total, we used 204 features to characterise each user in the dataset. We used that as input into a machine learning model for classifying users as hateful or normal.
The dataset also includes relationships between the users. A user is considered connected with another user if they re-tweet them. This relationship structure gives rise to a network that is different to Twitter’s network of follower and followee relationships.
Finally, users were labelled as belonging to one of three categories: hateful, normal, and other. Out of the roughly 100,000 users in the dataset, only around 5000 were manually annotated as hateful or normal. The remaining 95,000 users belong to the other category meaning they haven’t been annotated.
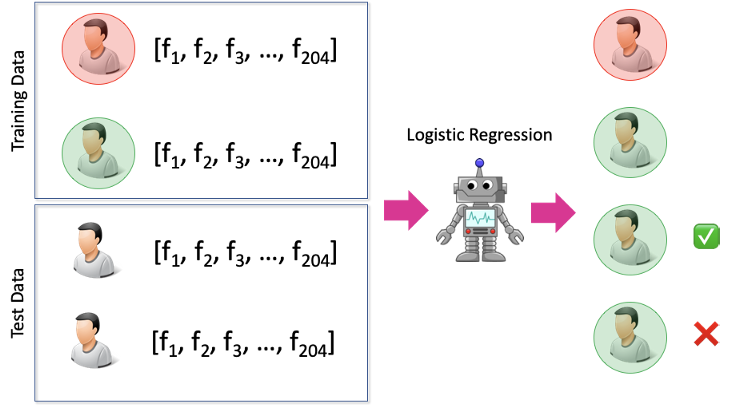
The setup for training and evaluating a logistic regression model for online hate speech classification.
Looking at things logically
We began by training a logistic regression model to predict a normal or hateful label for a user.
When training and evaluating this model, we ignored the 95,000 users that are not annotated as normal or hateful, as well as the relationships between users. This is due to lack of direct support for such information in logistic regression.
Graph Neural Network model (GraphSAGE)
The GNN model takes the user features and relationships between all users in the dataset. Including those users that are not annotated.
GraphSAGE introduces a new type of graph convolutional neural network layer. A specialised type of computer software inspired by biological neurons, a neural network is a method used to create artificially intelligent programs. In this case, the neural network model was designed to work with one, two or three-dimensional image data). This technique gathers information from a person, or in this case, their neighbourhood while training the machine.
So, while it’s looking at the individual user’s features it’s also layering it with those of its neighbours, perhaps their neighbours as well, and so on. Basically, it works on the assumption is that a hateful user is likely to be connected with other hateful users.
The outcome
Comparing the two machine learning models allowed us to see whether using the additional information about users and their online relationships actually helped to make a better classification.
Assuming we are willing to tolerate a false positive rate of approximately 2 per cent, the two models achieve true positive rates of 0.378 and 0.253 for GraphSAGE and logistic regression respectively.
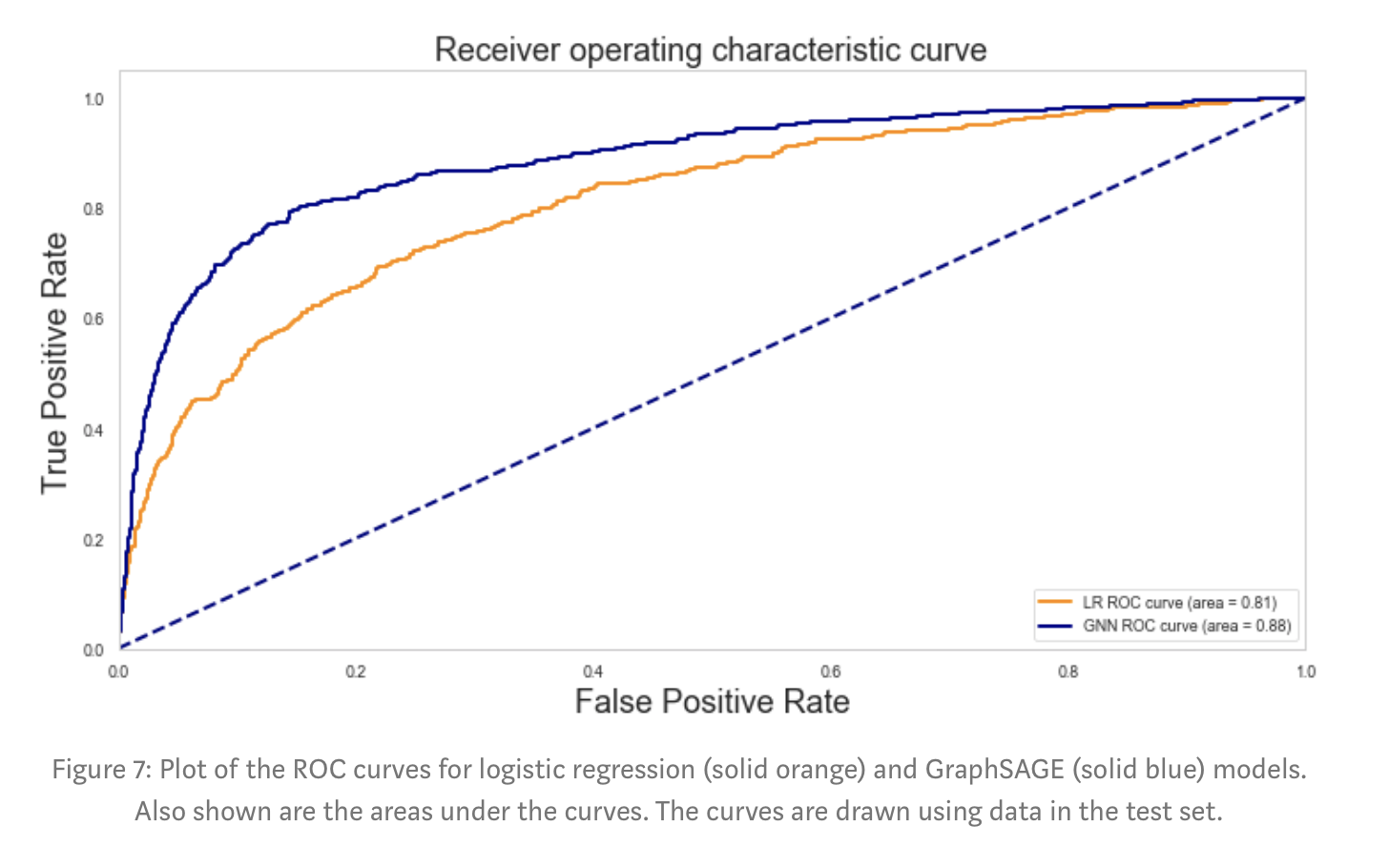
We can correctly identify more hateful users for the same low number of misclassified normal users. So, for a fixed false positive rate of 2 per cent, the GraphSAGE model achieves a true positive rate that is 12 per cent higher than the logistic regression model.
By using the relationship information available in the data, as well as the unlabelled user information, the performance of the machine learning model is greatly improved.
What we learned
This case study demonstrated that modern graph neural networks can help identify online hate speech at a much higher accuracy than traditional machine learning methods. It also demonstrated that graph machine learning is a suitably powerful weapon in the fight against online hate speech.
There is room for improvement. But the results certainly provide encouragement for additional research with larger network datasets and more complex GNN methods.
This is an extract from an original article published by StellarGraph’s Pantelis Elinas in collaboration with Anna Leontjeva and Yuriy Tyshetskiy on Medium. A condensed version of this article can be found on our DATA61 blog, Algorithm.
The world is plagued by digital deceit and data scandals. At D61+ LIVE, former CIA and FB advisor and strategist, Yael Eisenstat, will examine what data mistrust is now and how we can overcome it on the ‘Trust in a Trustless World’ panel. The event is free but save your spot and register now.

26th September 2019 at 12:28 am
Is the model publicly available? I’m trying to launch a social network and this would be invaluable!